
Quando criamos um sistema, é muito comum termos alguma forma de persistir dados, ou seja, guardá-los em algum lugar para, posteriormente, consultá-los. A forma mais comum de se fazer isso é por meio de Sistemas Gerenciadores de Banco de Dados (SGBD). O Java permite, não só acesso a eles, mas, também, a uma variedade de fornecedores e produtos como: MySQL, Oracle, SQL Server (Microsoft), PostgreSQL, entre outros. Neste artigo, veremos como o JDBC torna isso é possível, bem como uma “receita de bolo” para usarmos um banco de dados em nossos programas.
A API JDBC
Quando queremos acessar um banco de dados, é necessário se conectar e, depois, se comunicar com ele. Essa comunicação é feita por meio de um protocolo específico para cada produto e/ou fornecedor. Assim sendo, é muito comum termos alguma biblioteca de funções ou classes para fazer esse trabalho pesado. Normalmente, o próprio fabricante do banco de dados fornece essa biblioteca sob o nome de “driver de acesso”. E, seu programa “conversa” diretamente com esse “driver”. Isso significa que, se você precisar trocar o acesso do seu programa para outra “marca” de banco de dados, precisará de outro “driver” e, provavelmente, terá que alterar seu código porque a utilização dessa nova biblioteca será diferente. Imagina a dor de cabeça…

O Java possui uma API (Application Programming Interface) para acesso a banco de dados chamada JDBC (Java DataBase Connectivity). Essa API permite usar os “drivers de acesso” de forma transparente, isto é, independentemente da “marca” do banco de dados. Com isso, se sua aplicação fizer uso apenas de comandos SQL básicos, é bem provável que ela fique extremamente flexível em relação ao banco de dados que você for usar.
Mas, como isso é possível? Bom, isso é possível pelo bom uso dos conceitos de Programação Orientada e Objetos e mais alguns truquezinhos “avançados” (como Reflection, Service Providers, entre outros). No fim, a “mágica” toda fica por conta do polimorfismo. Vejamos como, observando a figura abaixo:
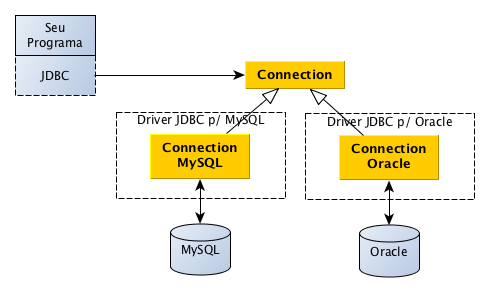
Note que o seu programa continua usando um driver, mas a “conversa” é feita indiretamente, por meio do JDBC e sua interface chamada Connection. Cada “Driver JDBC” implementa essa interface de forma específica para cada banco de dados. Usando os conceitos de Orientação a Objetos, seu programa “sabe” apenas da interface Connection, ficando livre de acessar classes e/ou funções específicas, ou seja, o código fica muito flexível. Observação: obviamente, o JDBC é composto por “muuuitas” outras interfaces e classes… Connection é apenas uma delas!
Mas, como é instanciado o objeto correto? Bom, o JDBC possui um classe chamada DriverManager que sabe ler uma configuração chamada “URL de conexão” (ou “string de conexão”) e, por meio dela, cria o objeto específico para o banco que se quer usar. Isso ficará mais claro logo abaixo, quando você vir o código! 😉
A Receita de Bolo
Para começar, saiba que precisamos, basicamente, de quatro informações para acessar um banco de dados:
- Nome completo (FQN) da classe que implementa o Driver JDBC.
- URL de conexão.
- Nome do usuário de acesso ao banco.
- Senha do usuário de acesso ao banco.
Para saber os dois primeiros itens, é necessário consultar o manual do Driver JDBC específico para o banco que você quer acessar. Ah! Lógico, você também irá precisar fazer o download do driver e colocá-lo junto ao seu programa (cada IDE faz de um jeito, mas, basicamente, a JVM irá acessa-lo por meio do CLASSPATH).
Por exemplo, se formos acessar um banco de dados MySQL, precisaremos fazer o download do Driver JDBC para MySQL e, olhando a documentação, saberemos que o nome completo da classe que implementa o Driver JDBC é “com.mysql.jdbc.Driver” e que a URL de conexão tem o seguinte formato: “jdbc:mysql://host:port/database“. Observação: para os exemplos deste artigo, estarei usando um banco de dados de exemplo do MySQL chamado “sakila“.
Uma vez que temos todas as informações, carregamos o driver e nos conectamos ao banco usando as seguintes linhas de código:
// informações necessárias String driver = "com.mysql.jdbc.Driver"; String url = "jdbc:mysql://localhost:3306/sakila"; String user = "root"; String pass = "god"; // carrega o driver Class.forName(driver); // faz a conexão Connection conn = DriverManager.getConnection(url, user, pass);
Consultas
Após obtida uma conexão, podemos enviar consultas ao banco de dados por meio de comandos SQL. Para isso, precisamos primeiro preparar a consulta e, depois, executá-la. Após isso, você obterá um conjunto de resultados pelo qual deverá iterar, verificando se tem um próximo resultado. Caso tenha, use-o como quiser! 🙂 Vamos ver o código devidamente comentado?
// sua consulta
String sql = "select * from customer order by first_name, last_name";
// prepara a consulta, por meio da conexão (conn)
PreparedStatement stmt = conn.prepareStatement(sql);
// executa a consulta, obtendo um conjunto de resultados (ResultSet)
ResultSet rs = stmt.executeQuery();
// itera pelo conjunto de resultados, perguntando se tem um próximo (next)
while (rs.next()) {
// se tem, obtém os campos que você quiser
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
// e, usa os valores aqui... exemplo: mostra na tela:
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
O interessante é que, ao se preparar a consulta, podemos colocar parâmetros nela. Como assim? Imagine que você quer consultar os “customers” que não estão ativos (active = 0) e que são da “store” 2 (store_id = 2). Podemos criar a seguinte consulta:
String sql = "select * from customer where active = 0 and store_id = 2 order by first_name, last_name";
No entanto, pode ser que esses valores (active = 0 e store_id = 2) possam ser passados pelo usuário, virem de uma variável, etc. Assim, seria interessante se deixássemos eles “em aberto”, por assim dizer. Fazemos isso dessa forma:
String sql = "select * from customer where active = ? and store_id = ? order by first_name, last_name";
Note que coloquei dois símbolos de interrogação “?“. O primeiro (1) deve ser substituído pelo valor 0 e o segundo (2) pelo valor 2. Para substituir, usamos o seguinte código:
// sua consulta String sql = "select * from customer where active = ? and store_id = ? order by first_name, last_name"; // prepara a consulta, por meio da conexão (conn) PreparedStatement stmt = conn.prepareStatement(sql); // configura os parâmetros da consulta stmt.setInt(1, 0); // o primeiro deve ser substituído pelo valor 0 stmt.setInt(2, 2); // o segundo deve ser substituído pelo valor 2
Veja que usamos os métodos setInt, setString, etc. para substituir os parâmetros por valores, da mesma forma que usamos os métodos getInt, getString, etc. para obter os valores dos campos no conjunto de resultados.
Atualizações
Nesse ponto, já sabemos como consultar o banco de dados. Mas, e se quisermos alterar (update) alguma coisa por lá? “Tipo”, se inserirmos, atualizarmos ou removermos dados, estaremos alterando (updating) o estado do nosso banco. Faz sentido? Bom, para fazer isso, o código é “beeem” parecido com o anterior. A mudança fica por conta do método que temos que chamar. Para executar a consulta (query), chamamos executeQuery. Para executarmos uma alteração (update), chamamos executeUpdate. Exemplo: se quisermos remover todos os “customers” que não estão ativos, escreveríamos o seguinte código:
// sua consulta String sql = "delete from customer where active = ?"; // prepara a consulta, por meio da conexão (conn) PreparedStatement stmt = conn.prepareStatement(sql); // configura os parâmetros da consulta stmt.setInt(1, 0); // colocar 0 na primeira interrogação int n = stmt.executeUpdate();
Note que o executeUpdate nos retorna um inteiro. Esse número indica quantas linhas foram alteradas, inseridas ou removidas da tabela em questão. É interessante verificar sempre esse valor. Assim, podemos ter uma ideia se o comando foi ou não executado com sucesso. Exemplo: se não tiverem “customers” inativos, o n será 0!
Fechando as Conexões
Como último passo da nossa “receita de bolo” para acesso a bancos de dados usando JDBC, é necessário finalizar, fechar a conexão com o banco de dados. Isso é importante porque, se não o fizermos, tanto o banco de dados como nosso programa passa a consumir recursos de máquina (memória, basicamente) de forma desnecessária.
Para fazer isso, a gente deve usar o método close() no objeto da classe Connection. No entanto, saiba que o ResultSet e o PreparedStatement também podem ser fechados. Ou seja, podemos deixar a conexão aberta, fechar apenas o conjunto de resultados, e reaproveitar a conexão aberta para fazer outra consulta. Aí, no final de tudo, deve-se fechar a conexão. Dessa forma, é importante seguir essa ordem no código:
rs.close(); stmt.close(); conn.close();
Tratando Erros
Como nem tudo são flores, muita coisa pode dar errado:
- O “driver” pode não estar instalado e, ao se tentar carregá-lo por meio do comando
Class.forName(driver);, uma exceçãoClassNotFoundExceptionpode ser gerada. - O banco pode estar “fora do ar” ou a rede pode estar com problemas. Nesse caso, ao se tentar uma conexão por meio do comando
DriverManager.getConnection(url, user, pass), umaSQLExceptionpode ser gerada. - Por conta desses mesmos erros citados no item anterior, a mesma exceção pode ser lançada pelos métodos
prepareStatement(sql),executeQuery(),executeUpdate(),next(),getString(...),getInt(...)e afins, etc.
Dessa forma, o nosso código deve tratar essas exceções usando try/catch e, principalmente, fechar a conexão e os outros objetos pertinentes no bloco finally. Com isso, garantimos a liberação dos recursos de máquina usados. Note que devemos fazer isso no bloco finally porque ele é sempre executado, mesmo que uma exceção não tratada seja lançada dentro do bloco try. Vejamos um código completo:
try {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/sakila";
String user = "root";
String pass = "root";
String sql = "select * from customer order by first_name, last_name";
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, user, pass);
PreparedStatement stmt = conn.prepareStatement(sql);
ResultSet rs = stmt.executeQuery();
while (rs.next()) {
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
} catch (ClassNotFoundException ex) {
System.out.println("Driver não encontrado!");
} catch (SQLException ex) {
System.out.println("Erro de banco: " + ex.getMessage());
} finally {
rs.close();
stmt.close();
conn.close();
}
Se você prestou atenção direitinho no código acima (ou se copiou-e-colou na sua IDE), deve ter notado que o bloco finally contém erros: as variáveis rs, stmt e conn não podem ser acessadas porque elas foram criadas dentro do bloco try, ou seja, em outro escopo. Para resolver isso, deve-se declará-las fora do bloco try/catch. Só que, com isso, precisamos verificar se essas variáveis não estão nulas e tratar a exceção que pode ser gerada pela chamada do método close(). Veja:
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/sakila";
String user = "root";
String pass = "root";
String sql = "select * from customer order by first_name, last_name";
Class.forName(driver);
conn = DriverManager.getConnection(url, user, pass);
stmt = conn.prepareStatement(sql);
rs = stmt.executeQuery();
while (rs.next()) {
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
} catch (ClassNotFoundException ex) {
System.out.println("Driver não encontrado!");
} catch (SQLException ex) {
System.out.println("Erro de banco: " + ex.getMessage());
} finally {
if (rs != null) { try { rs.close(); } catch (SQLException ex) {} }
if (stmt != null) { try { stmt.close(); } catch (SQLException ex) {} }
if (conn != null) { try { conn.close(); } catch (SQLException ex) {} }
}
Melhorando…
Existe uma outra forma de fazer esse tratamento de erros que evita que precisemos fazer toda essa verificação no bloco finally. O código está logo abaixo e a explicação no próprio link do artigo indicado…
try {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/sakila";
String user = "root";
String pass = "root";
String sql = "select * from customer order by first_name, last_name";
Class.forName(driver);
Connection conn = DriverManager.getConnection(url, user, pass);
try {
PreparedStatement stmt = conn.prepareStatement(sql);
try {
ResultSet rs = stmt.executeQuery();
try {
while (rs.next()) {
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
} finally {
rs.close();
}
} finally {
stmt.close();
}
} finally {
conn.close();
}
} catch (ClassNotFoundException ex) {
System.out.println("Driver não encontrado!");
} catch (SQLException ex) {
System.out.println("Erro de banco: " + ex.getMessage());
}
O código fica melhor, mas pode ser estranho para a maioria dos iniciantes… 😉
Melhorando mais ainda!
A partir da versão 7, o Java possui uma nova forma de fazer tratamento de erros chamada “try-with-resources“. Basicamente, ele foi feito especificamente para esse tipo de código que estamos tratando: os que precisam fechar conexões, arquivos, etc. Ele funciona assim:
try (Recurso1 r1 = CriacaoDo.Recurso1();
Recurso2 r2 = CriacaoDo.Recurso2()) {
// uso dos recursos r1 e r2 que podem gerar exceção...
} catch (ExcecaoASerTratada ex) {
// tratamento do erro...
}
O que mudou? Bom, a criação dos objetos que precisam ser fechados vão dentro dos parênteses. O que tiver aí será fechado automaticamente!!! “Muuuito” melhor, não? Vamos ver, então, como fica o nosso código:
try {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/sakila";
String user = "root";
String pass = "root";
String sql = "select * from customer order by first_name, last_name";
Class.forName(driver);
try (Connection conn = DriverManager.getConnection(url, user, pass);
PreparedStatement stmt = conn.prepareStatement(sql);
ResultSet rs = stmt.executeQuery()) {
while (rs.next()) {
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
}
} catch (ClassNotFoundException ex) {
System.out.println("Driver não encontrado!");
} catch (SQLException ex) {
System.out.println("Erro de banco: " + ex.getMessage());
}
“Muuuuuuito” melhor!!! Mas, você deve estar se perguntando, e se o SQL tiver parâmetros? Bom, aí temos que separar o bloco try em dois: um antes de estabelecer os parâmetros por meio dos métodos setString(..., ...), setInt(..., ...), etc. e outro depois, só para o ResultSet. Assim:
try {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/sakila";
String user = "root";
String pass = "root";
String sql = "delete from customer where active = ?";
Class.forName(driver);
try (Connection conn = DriverManager.getConnection(url, user, pass);
PreparedStatement stmt = conn.prepareStatement(sql)) {
stmt.setInt(1, 0);
try (ResultSet rs = stmt.executeQuery()) {
while (rs.next()) {
String nome = rs.getString("first_name");
String sobrenome = rs.getString("last_name");
int ativo = rs.getInt("active");
int loja = rs.getInt("store_id");
System.out.println(loja + " - " + nome + " " + sobrenome + " - " + ativo);
}
}
}
} catch (ClassNotFoundException ex) {
System.out.println("Driver não encontrado!");
} catch (SQLException ex) {
System.out.println("Erro de banco: " + ex.getMessage());
}
Conclusão
Vimos que o JDBC é uma API que pode acessar bancos de dados de forma independente. Também vimos que ele faz essa “mágica” por meio do uso dos conceitos de Programação Orientada a Objetos. Aliás, você notou que o único local do nosso código onde foi citado o MySQL foi nas configurações, mais precisamente dentro de uma string que poderia ter sido lida de um arquivo de configuração? Ou seja, nosso código mesmo nem sabe que está acessando o MySQL. Poderia ser o Oracle, o PostgreSQL ou qualquer outro!!!
Além disso, vimos os passos básicos de uma “receita de bolo” para usar o JDBC:
- Carrega o driver (
Class.forName) - Faz a conexão (
DriverManager.getConnection) - Prepara a consulta SQL (
prepareStatement+setXXX) - Executa a consulta (
executeQuery) - Itera pelos resultados (
next+getXXX)
No caso de comandos SQL que atualizam a base por meio de insert, delete ou update, a receita tem menos passos:
- Carrega o driver (
Class.forName) - Faz a conexão (
DriverManager.getConnection) - Prepara a consulta SQL (
prepareStatement+setXXX) - Executa a consulta (
executeUpdate)
Detalhe super importante que eu não comentei anteriormente, mas, se você estiver usando uma IDE, não precisou se preocupar: para usar as classes do JDBC é necessário fazer o import do pacote java.sql. De qualquer maneira, os códigos estão disponíveis no GitHub.
Espero que tenha gostado deste artigo e, caso queira se aprofundar no assunto, sugiro as seguintes leituras:
Até a próxima “aula”! 😉
olá professor,
Quais são as diferenças entre Statement e prepareStatement?
Olá, Joana.
Respondi sua pergunta aqui: Statement vs PreparedStatment: quais as diferenças?
Espero que seja útil!
[]s, Ramon
Parabéns Professor!
Muito bem explicado.
Oi, Marcos!
Obrigado pelo feedback!
Abraços!
Professor e no caso, eu fiz uma aplicação webservice que tem as strings de conexão com banco, mas eu preciso montar alguma tela para que o pessoal que utiliza a aplicação poder modificar a string de conexão, por exemplo apontar para produção ou dev… eu imaginei algo do tipo, uma tela onde solicita preenchimento do server, database, user e pass, mas eu teria que criptografar… para dar mais segurança ainda,,, você pode dar alguma sugestão? desde já agradeço.
Olá, couras.
Quando se trata de aplicações que executam em servidores (application servers como Tomcat, JBoss, etc.), existe uma solução muito melhor que é a configuração de um pool de conexões dentro do próprio servidor. Assim, você tem uma configuração para o banco de testes no servidor de testes e uma configuração para o banco de produção no servidor de produção. E sua aplicação “pede” para o servidor a conexão com o banco. Ou seja, independentemente de onde sua aplicação executar, ela vai ter a conexão correta.
Aí, você me pergunta “E como eu faço essa configuração?”. Bom, aí depende do application server. Cada um tem um jeito de fazer. Se você estiver usando o Tomcat 8, por exemplo, você precisa ler o manual do Tomcat 8 onde mostra a configuração de data sources.
Qual é o application server que você está usando?
[]s, Ramon
No caso seu eu fosse usar um banco de dados MariaDB, poderia usar o JDBC para MySQL ou teria que mudar?
Paulo,
Nesse caso, você tem que usar o driver JDBC para MariaDB, que pode ser obtido aqui: https://downloads.mariadb.org/connector-java/
[]s
Professor, to com uma duvida cruel para mim conseguir progredir no trabalho e java. Eu gostaria, de saber como “reutilizar” uma conexão ja feita no java. Exemplo, eu declaro uma conexão feita 1 vez só e toda vez que eu for necessitar de dados novamente, eu utilizo a mesma conexão, não precisando ficar abrindo e fechando, abrindo e fechando, toda vez. Teria como?
Obrigado pela atenção
Matheus,
Se você está fazendo um programa para desktop, reutilizar a conexão é mais uma questão de lógica: você pode, por exemplo, abrir a conexão no início do programa e passar a variável da conexão para os métodos/funções que precisam dela. Ou mantê-la em um atributo de classe (static). E lembre de fechá-la antes de sair do programa. No entanto, em uma aplicação desktop eu não vejo problema em ficar abrindo e fechando a conexão.
O mesmo não ocorre em uma aplicação para web, onde pode haver muitas requisições em pouco tempo. Nesse caso, ficar abrindo e fechando conexões pode ser um problema! É para isso que existem os “pools de conexões”. Um pool de conexões é um “componente” que abre várias conexões com o banco e gerencia a entrega delas para o seu programa. Ou seja, você delega essa responsabilidade de gerenciar essas conexões para ele, se preocupando apenas em pedir uma conexão, por meio de um “datasource”.
Quem sabe eu anime em gravar um vídeo (faz um tempo que parei com as aulas e não atualizei mais nada por aqui), mas, enquanto isso, você pode ver:
Atenciosamente,
Prof. Ramon